
目次
PythonでWEBスクレイピング
スクレイピング(Scraping)の英単語の意味は「こすり落としたもの・ひっかく」みたいな意味ですが、そこから派生して「データを収集した上で利用しやすく加工すること」の意味でも使われてます。
なので、「Web上から必要なデータを取得して加工する」することをWEBスクレイピングといいます。
Webスクレイピングは注意してやらないといけません
Pythonで毎回のデータ取得から加工までの一連の作業を自動化すると便利だよ・・とか、そういう話題によくでてくるのですが、インターネット上で提供されているデータの場所やレイアウト(HTML)が変わると、突然、うまくいかなくなったりします。
また、調子にのってやりまくると負荷をかけて、そのサイトに迷惑をかけてしまうことになったりするので、注意してやらないといけません。
WEBスクレイピングでやること
やることは。
- WebサイトからHTMLファイルをダウンロードする。
- HTMLファイルを解析して必要な部分のデータだけ抜き出す。
- 抜き出したデータを編集してEXCEL表形式で保存する。
です。
PythonのWebスクライピングで使うモジュール
それぞれ便利なpythonのモジュールがあるので、それを使います。
まだインストールされていないものについては以下でインストールします。
WebからHTMLファイルをダウンロードするモジュール
pip install requests
HTMLを解析して、必要なデータを抜き出すモジュール
pip install bs4
pip install openpyxl
世界経済のネタ帳サイトを対象にします
下記のサイトみたいな使えそうな表を提供してくれるサイトから、一覧表の部分(ランキングの表とか)だけを抜き取ってEXCELの表に自動的に変換します。
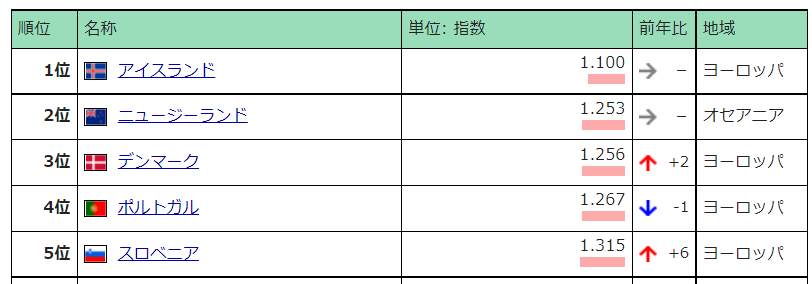
今回は「報道の自由度ランキング」のページです。
こちらにあるランキングの一覧表を対象とします。
プログラムする前の下調べ
データを「スクレイピング」するには該当ページのHTMLを調べる必要があります。
調べるには、Google Chromeのデベロッパーツールが便利です。
確認したい表にマウスをあてて、右クリックメニューから「検証」を選びます。

そうすると、デベロッパーツールが立ち上がってきて、ツール上のHTMLタグを選ぶと対応するWEB画面の場所が反転するので、非常に確認しやすいです。
今回の場合、以下のように目指す一覧表全体が反転する場所を見つければいいです。

このページの場合は、class="ranking_table"のDIVタグの内側の<table>タグに取得したいテーブルコンテンツがすべて収まっています。
なので、ranking_tableというクラス名のDIVタグの内側を、すっぽり抜き取ってしまい、そこに含まれる<table>の中身を抜き取って、EXCELの表に加工してやればよさそうです。
pythonプログラム
まずは、ソースです。
URLと出力ファイルを指定して、いろいろなランキングを一覧で取得できるようにクラスにしました。
import requests as web import bs4 import openpyxl as excel from openpyxl.styles import Font from openpyxl.styles import PatternFill from openpyxl.styles import Border from openpyxl.styles import Side from openpyxl.styles import Alignment import os class MakeRankingSheet(): def __init__( self, url='https://ecodb.net/ranking/bigmac_index.html', outfile='C:/tmp/output_ranking.xlsx'): self.__url = url self.__output_file_name = outfile.replace('/', os.sep) # 新規ワークブックオブジェクトを生成する self.__wb = excel.Workbook() # アクティブシートを得る self.__sheet = self.__wb.active # B2セルにタイトルを書くので、フォントサイズを24にして、センタリングする self.__sheet['B2'].font = Font(size=24) self.__sheet['B2'].alignment = Alignment(wrap_text=False, # 折り返し改行 horizontal='center', # 水平位置 vertical='center' # 上下位置 ) # B1などのrange指定文字列に変換する def __cell(self, col, row): col_ar = [ 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R'] return col_ar[col] + str(row) # 列番号を列を示す文字に変換する def __col(self, col): col_ar = [ 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R'] return col_ar[col] def get(self): res = web.get(self.__url) if(res.status_code == web.codes.ok): # パースしてDOMを取得する soup = bs4.BeautifulSoup(res.text, "html.parser") # タイトルを取得する。 title = soup.h1 self.__sheet.title = title.text self.__sheet['B2'] = title.text # ranking_tableクラスのDIVの内側にあるthタグをすべて取得する th = soup.select('div.ranking_table th') # セルを結合する self.__sheet.merge_cells('B2:' + self.__cell(len(th) - 1, 2)) # thタグをヘダーとして書き込み、背景色とボーダーをつける for h in range(len(th)): self.__sheet[self.__cell(h, 4)] = th[h].getText() self.__sheet.row_dimensions[4].height = 20 self.__sheet.column_dimensions[self.__col(h)].width = 17 self.__sheet[self.__cell(h, 4)].fill = PatternFill( patternType='solid', fgColor='E0FFFF00') self.__sheet[self.__cell(h, 4)].border = Border(outline=True, left=Side(style='thin', color='FF000000'), right=Side(style='thin', color='FF000000'), top=Side(style='thin', color='FF000000'), bottom=Side(style='thin', color='FF000000')) self.__sheet[self.__cell(h, 4)].alignment = Alignment(wrap_text=False, # 折り返し改行 horizontal='general', # 水平位置 vertical='center' # 上下位置 ) # ranking_tableクラスのDIVの内側にあるtdタグをすべて取得する td = soup.select('div.ranking_table td') index_max = len(th) for i in range(len(td)): # 1行5項目なので5で割ったり、5の余りをとったりしている c = i % index_max r = (i // index_max) + 5 # セルに値をセットする self.__sheet[self.__cell(c, r)] = td[i].getText() # セルの高さを20にする if(c == 0): self.__sheet.row_dimensions[r].height = 20 # 罫線を引く self.__sheet[self.__cell(c, r)].border = Border(outline=True, left=Side(style='thin', color='FF000000'), right=Side(style='thin', color='FF000000'), top=Side(style='thin', color='FF000000'), bottom=Side(style='thin', color='FF000000')) # 横方向は標準、縦方向は中央にする self.__sheet[self.__cell(c, r)].alignment = Alignment(wrap_text=False, # 折り返し改行 horizontal='general', # 水平位置 vertical='center' # 上下位置 ) else: res.raise_for_status() # EXCELブックを保存する self.__wb.save(self.__output_file_name) MakeRankingSheet().get()
Pythonプログラムの使い方
上記クラスをインポートして、以下のようにします。
デフォルト
MakeRankingSheet().get()
c:\tmp\output_ranking.xlsxファイルを出力します。
無指定の場合はこのランキングを表示します。
世界平和度指数ランキングのURLを指定して、アウトプットを「c:/tmp/output2.xlsx」にする場合は。
のようにすると。
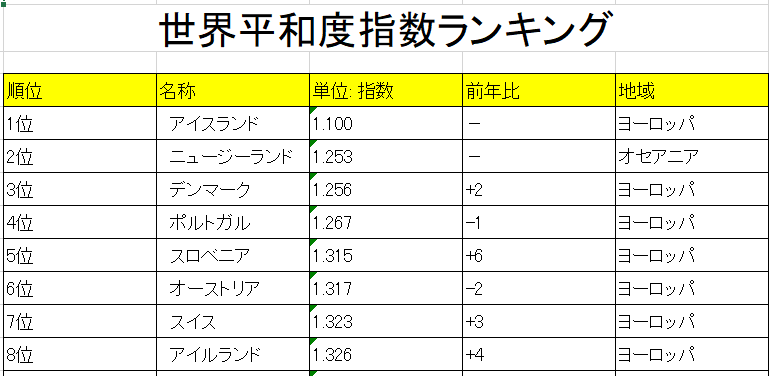
こんな感じのEXCELシートが作成されます。
ソースの補足説明
HTMLの解析には「Beautifulsoup」を使ってますが、CSSセレクターで取り出して、文字列だけ取り出すくらいのことしかしてません。
CSSセレクターは知らないとできないので、以下を参考にしました。
EXCELの操作はシートのセルごとに、連結したり、罫線をつけたりしているので、ソースがごちゃごちゃしてますが、やってること自体はごく基本的なことしかしてません。
いちおう、自分が参考にしたリンクをのせておきます。
本家のリファレンスのリンクをのせておきます。
(残念ながら英語ですけど)
今回はこんな感じで。
ではでは。