
目次
音楽(曲)を機械学習データに使える画像データにする
音楽(曲)を波形に変換して、それを画像ファイルにします。
そうすることで、機械学習の学習データとして使えるようになります。
音楽データの入手
音楽データはこれを使います。
この中にある「genres.tar.gz」です。
約1.1GBほどある巨大なファイル群です。
解凍すると、以下のようなフォルダ構成になってます。

この各フォルダの中にAU形式(UNIX等で利用される音声ファイル形式)の曲データがあります。

音楽を波形(スペクトラム)に変換する
曲データを画像データにする前に波形データにしてやる必要があります。
音声や地震波などの周期性のある信号は、どれだけ複雑な信号であっても、単純な波に分解できるという「フーリエの定理」を使うと、波形(周波数成分と振幅成分を抽出した周波数スペクトラム)に変換できます。
実際に、音楽データを機械学習の学習データに使うためには、単純な波形(スペクトラム)にするだけではなく、対数をかけて、さらにフーリエ変換をかけて、ヒトの周波数知覚特性を考慮した重み付けをするなどの加工を施して「メル周波数ケプストラム係数(Mel-Frequency Cepstrum Coefficients)」を求めて、それをグラフで可視化したものを使うことになっています。
この「メル周波数ケプストラム係数」の詳しい説明は、僕にはできません。
気になる方は、こちらをご覧ください。
とりあえず、そういうもんだ・・ですすめます。
pythonのlibrosaを使う
有難いことに。
pythonのlibrosaというモジュールを使うと、この難しい「メル周波数ケプストラム係数」を簡単にサクッと求めることができます。
librosaは
pip install librosa
でインストールしておく必要があります。
あと、グラフ化するのに「matplotlib」も必要です。
はいってなければ。
pip install matplotlib
でインストールします。
Pythonで音楽データを画像ファイルに保存するソース
曲ファイルを読み込んで「メル周波数ケプストラム係数」を求めて、matplotlibでグラフにしたものをPNG画像で保存するソースです。
import librosa import librosa.display import matplotlib.pyplot as plt import os def save_png(filename, soundpath, savepath): # オーディオファイル(au)を読み込む music, fs = librosa.audio.load(soundpath + filename) # メルスペクトラム(MFCC)変換 mfccs = librosa.feature.mfcc(music, sr=fs) # グラフに変換する librosa.display.specshow(mfccs, sr=fs, x_axis='time') # PNG形式画像で保存する plt.savefig(savepath + filename + '.png', dpi=200) soundpath = '.\\in\\au-data\\' savepath = '.\\out\\au-img\\' cnt = 0 for filename in os.listdir(soundpath): cnt += 1 if((cnt % 10) == 0): print(cnt, '件を処理しました') save_png(filename, soundpath, savepath)
上記 は「.\in\au-data\」フォルダに、au形式データをおいて、「.\out\au-img\」に生成した画像を置きます。
生成された画像サンプル
生成された画像はこんな感じです。

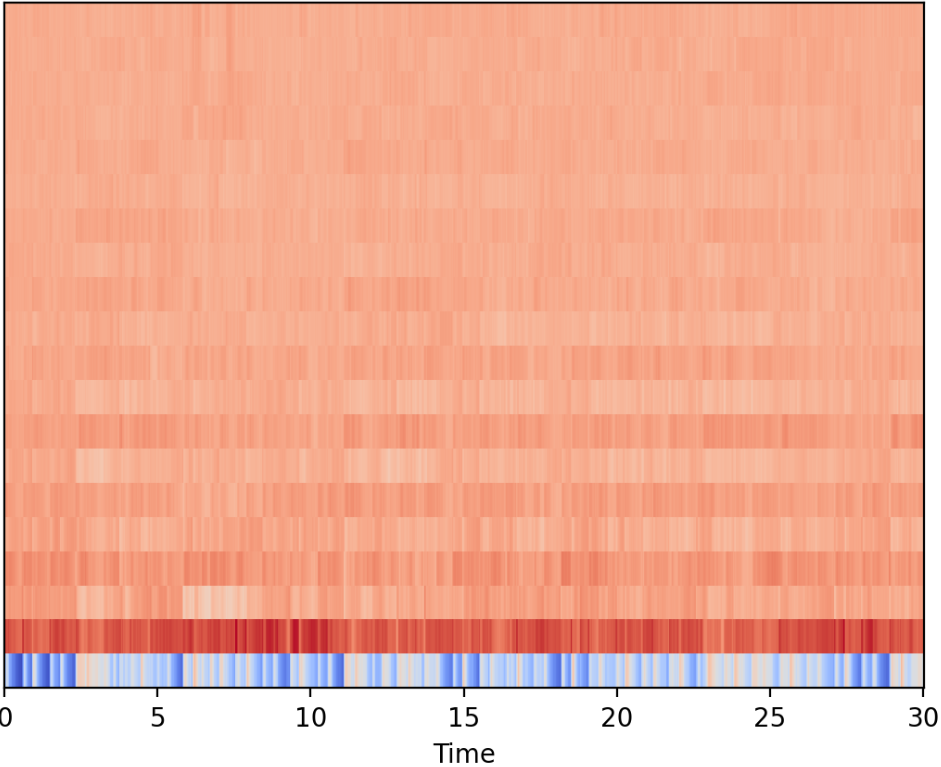
確かに曲によって微妙な違いがあります。
これを学習させれば音楽の分類ができる・・と、まあ、そういうことのようです。
ちなみに。
PNG画像で保存すると、αチャンネルがつき、RGBとあわせて4チャンネルになります。
だから、JPEGにするかどうかとか、生成された画像が大きすぎたら後にリサイズをするかどうかとかを考えてやる必要はありそうですけどね。
ではでは。
※この記事は機械学習の記事から前処理部分だけを抜粋してリライトしました。