
目次
MariaDBのインデックスについてざっくり整理
MariaDBのインデックスについて整理してみます。
まずは、基本的なことの押さえから。
インデックスがきくとかきかないとか
インデックスはデータベースで目的のレコードを効率よく取得するためのものです。
インデックスはテーブル内の特定の列を識別する値(キー値)と、それで特定されるデータが格納されている位置を示すポインタで構成されているので、インデックスを参照できれば目的のデータの格納位置に直接アクセス=検索を高速化できる仕掛けです。
インデックスではデータ量が大きくても速く検索できることが期待できるアルゴリズム(B-tree/B+ Treeが代表的ですが、クラスタインデックスとかビットマップインデックスとか色々あります)が採用されています。
仕事では「インデックスがきいてる」とか「きいてない」みたいな会話をしますが、このインデックスがきいている=インデックスが活用されて高速に検索ができているた・・と理解しておけばいいです。
MariaDB(MySQL)には、explainという便利なツールがあって、この出力の「Type列」を見ると、インデックスの適用有無や、どの種類のインデックスが適用されているかなどを確認できます。。
インデックスの用語と種類など
用語的な話でいうと「KEY」と「INDEX」 は通常同じ意味で使用します。
なので、インデックスの種類には「KEY」と「INDEX」がまじってます。
- primary keys:一意で null を許さない
- unique indexes:一意で null の可能性がある
- plain indexes:必ずしも一意であるとは限らない
- full-text indexes:全文検索用
primary keys(プライマリキー)は、「Create table」文で.「primary keys」を作成するときに自動的にインデックスも作成されます。
そのほかのインデックスは「create index」文で作成します。
primary keys(プライマリキー)インデックスは、create index文では作成できません。
また、InnoDBテーブルの場合、すべてのインデックスにプライマリキーが含まれてしまうので、できるだけプライマリキーは小さく使うのがセオリーになってます。
さて。
知識的なことはこのへんにして、インデックスがきく・きかないで、どの位差がでるのか?についてテスト用に1万行くらいのテーブルを3つほど用意して実際に試してみようと思います。
インデックスの有無は1万行くらいだとあまり関係ない
まずは、テーブル単体でSelectしてみます。
上記のようなテーブル(blog_c)を、インデックスをはってあるカラム(id)とインデックスをはってないカラム(start_date)をwhere句で使ったケースで比べてみます。
インデックスがはってあるケース。
SELECT * FROM blog_c WHERE id >= 100 AND id <= 1000;
実行結果は「901件のデータを取得し、 時間は「0.03957秒」でした。
でも、インデックスがはってないケースでも・・
SELECT * FROM blog_c WHERE start_date >= ’2022-01-01' AND start_date <= '2025-01-01';
実行結果は「916件」のデータを取得し、時間は「0.03561」秒です。
たいして変わりません。
10000行程度のデータ量だと、テーブルをALLでスキャンしても、インデックスを使っても大して変わらない・・みたいです。
インデックスの有無は扱う行数が増えると差がでてくる
今度は2つのテーブルをJOINしてみます。
2つ目のテーブル(blog_b)はこんな感じです。

この2つをJOINして、まずは、JOINのキーにインデックスがはってあるカラム(id)を使ったほうをやってみます。
JOINのキーに着目したいので、WHERE句はあえて、インデックスのないカラム(start_date)を指定してます。
SELECT T1.id FROM blog_c T1 join blog_b T2 on T1.id = T2.id WHERE T1.start_date >= ’2022-01-01' AND T1.start_date <= '2025-01-01';
結果は。
取得件数が「:916件」で 時間は「0.0216549秒」でした。
今度は、JOIN条件にインデックスをはっていないカラム「code」を使います。
SELECT T1.id FROM blog_c T1 join blog_b T2 on T1.code = T2.code WHERE T1.start_date >= ’2022-01-01' AND T2.start_date <= '2025-01-01';
すると、取得件数は「916件」で同じですが 時間は「2.3660982秒」・・なんと、109倍も遅くなりました。
ExplainをとってType列をみると、前者ではいちおうインデックスをつかっていて

後者はType列が両方とも「ALL」つまり全テーブルスキャンでインデックスを使っていないことがわかります。

とはいえ。
インデックスを使っているとはいえ、前者も問題は残ってます。
T2テーブルのType列が「index」になっているからです。
この意味は「使用されているインデックスをフルスキャンしている」です。
これは、「ALLよりマシだけど、インデックスが大きくなったら遅くなる可能性が高い」ということを意味します。
なので・・例えば。
SELECT T1.id FROM blog_c T1 join blog_b T2 on T1.id = T2.id WHERE T1.start_date >= ’2022-01-01' AND T1.start_date <= '2025-01-01' and T2.id >= 1;
みたいに、where句にT2のテーブルのインデックスがはってあるカラムでの絞り込み条件を追加してやると、より速くなるはずです。
やってみたら、件数は「916件」で変わりませんが、時間は「0.01540829秒」とわずかながらに改善しました。
EXPLAINの結果のtype列も

のように両方とも「ALL」でも「index」でもなくなりました。
インデックスは、なるほど微妙です。
インデックスは横着にはっても意味があまりない
もう一つJOINするテーブルを追加してみます。
blog_aです。
今度はWHERE句でインデックスのあるカラム(id)を使い、JOINのキーはインデックスのないカラム(code)を使ってこんな感じのSQLにします。
SELECT T1.id FROM blog_c T1 join blog_b T2 on T1.code = T2.code join blog_a T3 on T1.code = T3.code WHERE T1.id >= 100 AND T1.id <= 1015;
この実行結果は「916件」で 時間は「2.841486秒」です。
EXPLAINの結果も、こんな感じ。
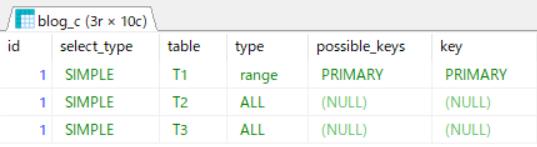
T2とT3がALL(テーブルフルスキャン)になってます。
ここで各テーブルの「id」「start_date」「code」カラムにインデックスをはります。
create index blog_a1idx on blog_a(id,start_date,code);
create index blog_b1idx on blog_b(id,start_date,code);
create index blog_c1idx on blog_c(id,start_date,code);
なんとなく、クエリに登場する可能性のあるカラムをまとめてインデックスに含めておくみたいな考え方の「横着なインデックス」です。
よくない・・とは言われますが、これで上記のSQLがどうなるか試してみます。
実行してみると、件数「916件」で、 時間は「3.1539116秒」。
遅くなりました(笑)
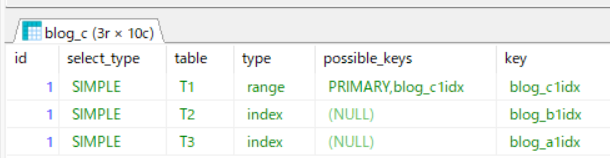
追加したインデックスは使われてますが、T2とT3が「index」(インデックスフルスキャン)なのと、T1がプライマリインデックスでなくなったので、遅くなった・・ということなんでしょうね。
横着なインデックスがよくないのはよくわかっらので、いったん削除して、以下のようにしてみます。
create index blog_a1idx on blog_a(code);
create index blog_b1idx on blog_b(code);
blog_cテーブルはもともとプライマリキーでインデックスされているので、JOINするテーブルのキーカラムにだけインデックスをつける感じです。
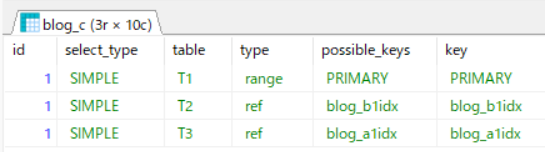
実行結果は、件数「:916件」 時間は「0.028226秒」で、約100倍ほど速くなりました。
EXPLAINしてもしっかりと、インデックスが使われてます。
まとめ
適当なテーブル・ケースではありますが、インデックスについて試してみました。
正直。
だから・・どうした?という程度の内容だと自覚はしてます(笑)。
でも、こういうのは、なんとなく結果の推測はできますけど、仮説をたてて、ためしてみて結果を見るみたいなチューニングの場数を踏むしかない面もあるので、こんなことでも「やらないよりは、やったほうがベター」だと僕は思ってます。
ではでは。